




One of the main difficulties that people encounter when trying to build their edge ML models is gathering a large, yet simultaneously diverse, dataset. Audio models normally require setting up a microphone, capturing long sequences of sounds, and then manually removing bad data from the resulting files. Shakhizat Nurgaliyev’s project, however, eliminates the need for the arduous process by taking advantage of generative models to produce the dataset artificially.
In order to go from three audio classes: speech, music, and background noise to a complete dataset, Nurgaliyev wrote a simple prompt for ChatGPT that gave directions for creating a total of 300 detailed audio descriptions. After this, he grabbed an NVIDIA Jetson AGX Orin Developer Kit and loaded Meta’s generative AudioCraft model which allowed him to pass in the previously made audio prompts and receive sound snippets in return.

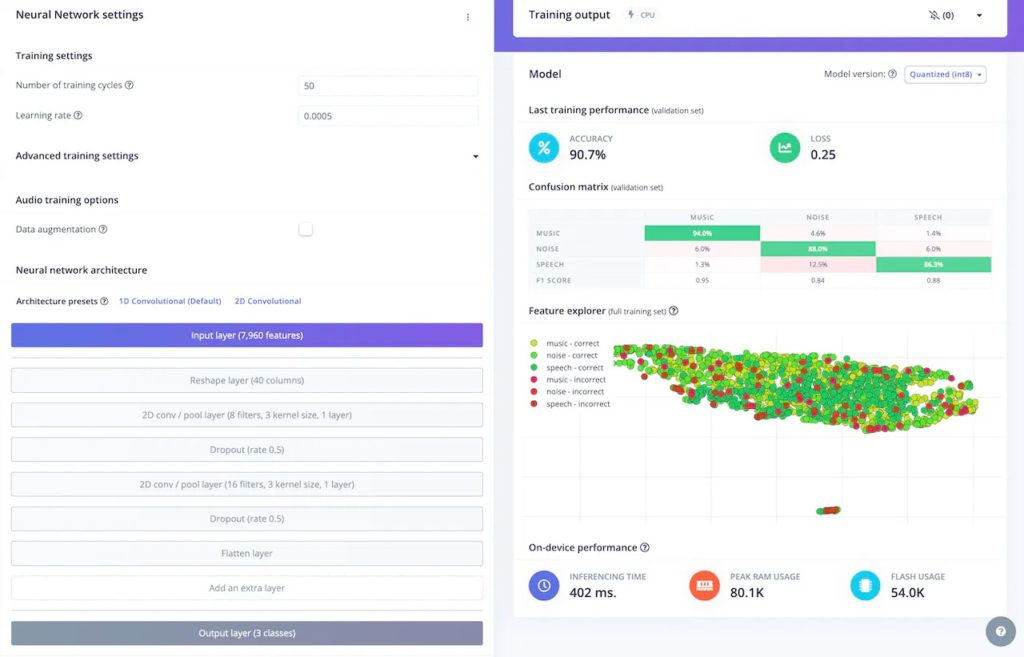
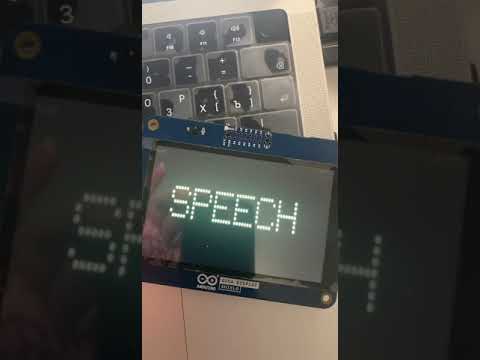
The final steps involved creating an Edge Impulse audio classification project, uploading the generated samples, and designing an Impulse that leveraged the MFE audio block and a Keras classifier model. Once an Arduino library had been built, Nurgaliyev loaded it, along with a simple sketch, onto an Arduino GIGA R1 WiFi board that continually listened for new audio data, performed classification, and displayed the label on the GIGA R1’s Display Shield screen.
To read more about this project, you can visit its write-up here on Hackster.io.
The post Classifying audio on the GIGA R1 WiFi from purely synthetic data appeared first on Arduino Blog.
Website: LINK

